The main engineering goal of Litmus is to re-use as much existing content and external code as is feasible. Smaller re-usable components and leveraging functionality of other projects allows for easier adaptation and allows Litmus to ride along on the success of others, like bolt. It also means that it is easier to replace the parts that did not turn out to fulfill the needs of the users.
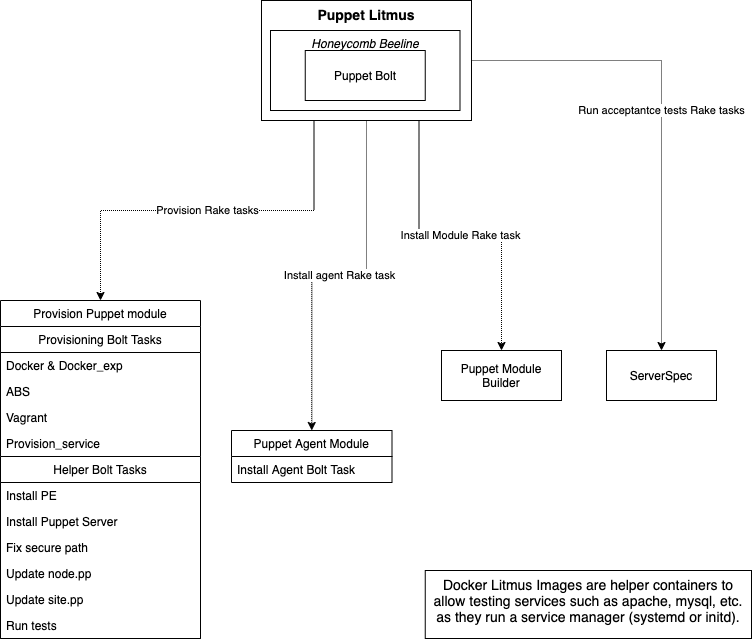
Components
The following list is the current set of components and implementation choices. Some of those choices are pure expediency to get something working. Others clear strategic decisions to build a better-together story.
- UI: litmus rake tasks
- Communication Layer: bolt
- Configuration:
provision.yaml- CI job setup
spec/fixtures/litmus_inventory.yaml- test dependencies: .fixtures.yml
- Test Infrastructure:
- puppetlabs-provision module
- hypervisors: docker, vagrant, vmpooler, abs
- external provisioners: e.g. terraform
- test systems:
- litmusimage
- upstream images
- custom images
- utility code
- puppetlabs-facts module
- puppetlabs-puppet_agent module
- Test Tracing: honeycomb
- Testing System
- runner: RSpec
- test case definition: RSpec
- test setup:
- a manifest string embedded in the test case
- ruby code to orchestrate a change
- test assertion
- serverspec
- hand-coded checks
- Packaging and delivery:
- Litmus as gem
- Litmus as PDK component
- utility modules as git repos
- bolt as gem
The following sections go over the various components, their reasoning and discuss alternative options.
UI
The current UI/UX of Litmus is implemented as a set of rake tasks in puppet_litmus:lib/puppet_litmus/rake_tasks.rb.
Reasoning: Rake is a ubiquitous choice of interacting with a set of connected tasks in the ruby world. The limited option parsing capabilities push the design towards simple interactions and storing important information in configuration files. It is very easy to get started with a project based on rake tasks, as there is a wealth of examples and tutorials on how to build rake tasks.
Alternatives:
As the Litmus workflow and configuration matures we might want to consider a dedicated CLI with more ergonomic option parsing possibilities.
This could be implemented as part of the pdk (pdk test acceptance) or a standalone CLI tool shipped as part of the PDK.
The VSCode plugin could provide additional UI to make running and interacting with acceptance tests directly from the IDE possible.
Communication Layer
The communications layer for litmus needs to be able to talk to all the various systems that users might want to use in testing.
Reasoning: Bolt supports SSH, WinRM natively and allows extension to other remote protocols using Puppet’s extension points. With Bolt being integrated into our entire product line, re-using it also for content testing is an easy choice. Content generated for Bolt can be re-used within tests, and vice versa. This allows users to re-use skills acquired and strenghtens Puppet’s better-together story.
Alternatives: Bolt as communication layer touches most other components and - while having a well-defined interface - would not be easy to replace. There is currently no reason to consider alternatives to Bolt.
Configuration
Configuration for Litmus currently is spread over several files.
The provision.yaml contains various lists of platforms to target for tests.
The CI job setup (usually in .travis.yml, appveyor.yml or similar) contains the overall sequencing of steps for testing.
This setup is usually the same everywhere and is encoded in pdk-templates.
There are slight variations to choose the puppet version and platform combinations from provision.yaml.
Last but not least, transient state and roles of provisioned systems is stored in Bolt’s inventory.yaml.
The inventory is usually managed by Litmus as an implementation detail.
In advanced scenarios users can create, add, edit, or replace the inventory in pursuit of their use cases.
Reasoning: The current set of configurations is the absolute minimum to get Litmus working. Most of the files are inherited from existing practices and tools.
Alternatives: While the current set of configuration files works for now, it’s main purpose is to carry Litmus over this phase and highlight the requirements for the next iteration.
- Replace scattered configuration with a Boltdir that can contain all the module-specific info required
- Replace .fixtures.yml with
Boltdir/Puppetfilefor unit and acceptance testing - Investigate/implement pdk/litmus specific
Boltdirlocation/name to avoid colliding with production use of a Boltdir - Get test-hiera data/config from
Boltdir/databy default
- Replace .fixtures.yml with
- The current setup of (re-)writing the inventory is problematic as it deprives advanced users of safe ways to enhance the inventory to suit their needs
- Example: custom SSH key/options
- Bolt has now plugins to receive inventory information from outside sources - would this be a good way to keep dynamic litmus data out of inventory.yaml?
- Find ways to pass arguments to provisioners
- Hypervisor Credentials and arguments
- bolt options (e.g custom SSH key/options)
- which parts of this are module/repo specific? which parts need to be per-user?
Test Infrastructure
For full system-level testing of acceptance criteria, tests require access to systems to test. Depending on the use-case and resources available, this test infrastructure can be accessed in a variety of ways. There are a few necessary conditions for all those test systems:
- accessible through bolt - this allows tests to act on such a system
- initially clean - without a well-defined initial state, tests become complex, unreliable, or both
- dedicated - running tests on shared systems is inviting troubles, either by tests stepping on each other or the tests interfering with user activities or the other way around
- representative of production systems - running the tests should provide insight about expected behaviour in the real world
What can be used as Test Infrastructure?
Throw-away VMs are the easiest way to fulfil those conditions. Provisioned from upstream images or organisations’ golden templates, they provide a complete operating system, accurate representation of production and full isolation. The downside of virtual machines are the high resource usage and provisioning times in the order of minutes. You can use local VMs on your development workstation, or private and public cloud providers.
To reduce resource usage and provisioning times docker and containers come in handy. They deploy in seconds and achieve high packing densities with low overhead. Best practices for container images justifiably frowns on SSH access or complete operating system services, thus common public images are usually not representative of production on full VMs. To avoid this limitation, puppetlabs/litmusimages provides a set of pre-fabbed docker images that allow SSH access and have an init process running.
In some cases, using bare metal servers or already running systems is unavoidable.
How to provision Test Infrastructure
There are as many ways to aqcuire access to test systems as there are kinds of test systems.
By default, Litmus calls out to a provisioner task to provision or tear down systems on demand.
In the puppetlabs-provision module, we ship a number of commonly needed provisioners for docker (with SSH), docker_exp (using bolt’s docker transport), vagrant (for local VMs) and the private cloud APIs VMpooler and the puppet-private ABS.
Since Litmus 0.18 the rake tasks also allow calling arbitrary tasks outside the provision module to provision test systems. Daniel’s terraform demo shows one application of this.
The provision task will allocate/provision/start VMs or containers of the requested platforms and add them to the spec/fixtures/litmus_inventory.yaml file.
Through the use of the inventory file Litmus can also consume arbitrary other systems by users supplying their own data, independently of Litmus’ provision capabilities.
Alternatives
There are a number of opportunities to improve today’s provision capabilities.
- image customisation:
To make images usable with litmus, some customisation and workarounds need to be applied.
Be that installing SSH (litmusimage), removing tty handling (
fix_missing_tty_error_message), configuring root access (dockerprovisioner), configure sudo access (vagrantprovisioner) or installing pre-reqs to install the agent (wget/curl/etc). These workarounds are distributed across different components at the moment. Collecting all of them into the image baking process (litmusimage) would- make the provisioning code path easier and faster
- allow users to discover litmus’ requirements for custom images by inspecting the litmusimage build process
- reduce “magic” happenings when using custom images
- move inventory manipulation from provisioning tasks to litmus:
Currently provisioning tasks are required to update the
spec/fixtures/litmus_inventory.yamlfile with new target information and remove targets from thespec/fixtures/litmus_inventory.yamlfile on tear down. This causes a number of problems:- code duplication
- prohibits running provisioners in parallel
- unnecessarily pushes some operations (see
varshandling) into provision tasks - requires provision tasks to run on the caller’s host
Instead of writing directly to
spec/fixtures/litmus_inventory.yamlfile the provision tasks could return bolt transport configuration as part of the task result data. Litmus could then process that data as required in the work flow. Provisioners could now run in parallel and Litmus can coalesce the data at the end into aspec/fixtures/litmus_inventory.yamlfile. This approach requires only minimal code in the task (return data as JSON).
- allow more granular data than the platform name: Some provisioners could benefit from additional parameters passed in. For example choosing a specific AWS zone, VPC, GCP project or tags to host the test systems. This change also interacts with changes to how configuration data is stored. See ‘Configuration’ section above.
Utility Code
Litmus makes use of the puppetlabs-facts and puppetlabs-puppet_agent modules for some key operations.
Reasoning: These modules are maintained and used in other parts of the ecosystem already. Reusing them provides for a consistent behaviour across different products and additional value gained from the existing development and maintenance effort.
Alternatives: None required at the moment.
Test Tracing
For puppet-internal use we have instrumented Litmus and RSpec with Honeycomb. This is a optional component that is deactivated by default.
Reasoning: As the IAC team is maintaining ~50 modules’ test suites across Travis CI, Appveyor and Github Actions, we were looking for a unified way to keep track of everything that is going on. While not originally designed for it, Honeycomb fit the bill easily.
Alternatives: None required at the moment.
Testing System
This section covers all the things concerned with defining and executing the test cases.
Test Runner
RSpec is a mature and widely used unit-testing framework in the Ruby Ecosystem. We are maintaining mature integrations for Puppet catalog-level unit testing and there is a rich ecosystem of adjacent tooling by the puppet community.
Rationale: Using an existing product keeps us from re-inventing the wheel. RSpec has a host of already built in features and an ecosystem of plugins as well as tutorials and documentation. We’ve been able to adapt RSpec to our needs by using existing extension points. RSpec allows for fine-grained and dynamic test-selection, and provides excellent feedback to the user.
Alternatives: None required at the moment.
Test Case Definition
While RSpec’s fine-grained test setup capabilities are very necessary and useful for unit testing, the same capabilities have reduced applicability when looking at acceptance testing. These system-level tests usually have a lot more setup requirements and fewer, but more specialised tests.
Rationale: RSpec test case definition language was chosen by default as part of the RSpec test runner in the early stages of the evolution of Puppet test practices.
Alternatives: For a while cucumber-puppet was developed by some as an alternative but never gained as much traction or support in the Puppet community.
Test Setup
The test setup describes the necessary steps to reach the state to test. In litmus this is currently implemented by a mix of manifest strings embedded in ruby and litmus’ ruby DSL calls.
Rationale: This style of test setup is inherited from beaker-rspec and “The RSpec Way”.
Alternatives: Creating RSpec extensions for acceptance testing - like rspec-puppet does for unit testing - to represent common patterns would allow for crisper test setup definition. The additional abstraction could allow for more clarity and efficiency in setting up tests.
Test Assertion
After a test scenario is set up, assertions are executed to understand whether or not the original expectations are met. This can be as simple as checking a file’s content to as complex as interacting with an API to check its behaviour.
In acceptance tests the first way to check a system’s target state is idempotency.
This is implemented as first-class operation idempotent_apply in the Litmus DSL.
To ascertain that a service is not only working, but also correctly configured more in-depth checks need to be implemented in ruby. serverspec is preconfigured inside Litmus to allow for checking a number of common resources.
Other checks can be implemented in plain ruby or RSpec as required.
Rationale
Tests derive value from being easier to understand than the code under test. Through this they provide a confidence that merely reading the business logic (or, in Litmus’ case the manifest) does not support.
If puppet runs the same manifest a second time without errors or changes, this already implies that the desired system state has been reached. In many cases - for example when managing services - this is a more in-depth check that a test could do on its own. A service starting up and staying running implies that its configuration was valid and consistent. This is a check that would be very hard, nay prohibitively expensive, to implement in a test. Idempotency checking makes this (almost) free.
Serverspec was created for acceptance testing infrastructure. It integrates nicely with RSpec. Serverspec provides resources and checks that are currently not expressible in puppet code, like “port should be listening” or partial matching on file contents.
Alternatives
- Chef’s InSpec was forked from serverspec and developed by Chef.
- Selenium automates browsers and arguably could be used to check the health of a service deployed for testing.
- Any kind of monitoring or application-level testing framework that is already used for a specific service could be used to create insight into the health of said service.
Packaging and Delivery
-
Litmus is currently released as a gem first.
Rationale: In this phase of development this allows for rapid iteration. Deploying gems is well-understood in the development community.
-
Litmus is also shipped as part of the PDK.
Rationale: As an experimental part of the PDK Litmus becomes available offline to those who otherwise would need to cross air-gaps. At the same time, this also ensures that all the required dependencies are available in a PDK installation. Specifically this also would notify us if Litmus adds a dependency that is not compatible with the PDK runtime.
-
The Utility Modules are currently by default deployed into a test run directly from github.
Rationale: Expediency and speed.
Alternatives: To avoid poisoning test environments with litmus’ implementation details and better support offline work, the utility modules should be packaged up as part of the litmus gem and sourced from a private modulepath when needed. Grouping all content in that way enhances confidence that it is a fully tested package. This would also require more integrated testing and more frequent litmus releases to make changes available.
-
bolt is currently consumed as a gem
Rationale: Litmus is tightly bound to specific internal APIs and its dependencies. Depending on a gem provides flexibility in consuming bolt updates as Litmus is ready for it. Using the gem avoids any environmental dependencies and support issues arising from version mismatches.
Alternatives: Require bolt to be installed from its package.